分布式锁的实现原理
发布时间: 2024-12-01 11:21:01
介绍分布式锁的实现原理。
一、分布式锁概述
分布式锁,顾名思义,就是在分布式环境下使用的锁。众所周知,在并发编程中,我们经常需要借助并发控制工具,如 mutex、synchronized 等,来保障线程安全。但是,这种线程安全仅作用在同一内存环境中。在实际业务中,为了保障服务的可靠性,我们通常会采用多节点进行部署。在这种分布式情况下,各实例间的内存不共享,线程安全并不能保证并发安全,如下例,同一实例中线程 A 与线程 B 之间的并发安全并不能保证实例 1 与实例 2 之间的并发安全:
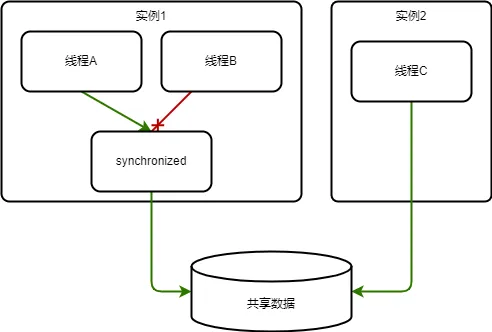
因此,当遇到分布式系统的并发安全问题时,我们就可能会需要引入分布式锁来解决。
用于实现分布式锁的组件通常都会具备以下的一些特性:
-
互斥性:提供分布式环境下的互斥原语来加锁 / 释放锁,当然是分布式锁最基本的特性。
-
自动释放:为了应对分布式系统中各实例因通信故障导致锁不能释放的问题,自动释放的特性通常也是很有必要的。
-
分区容错性:应用在分布式系统的组件,具备分区容错性也是一项重要的特性,否则就会成为整个系统的瓶颈。
目前开源社区中常见的分布式锁解决方案,大多是基于具备集群部署能力的 key-value 存储中间件来实现,最为常用的方案基本上是基于 Redis、zookeeper 来实现,笔者将从上述分布式锁的特性出发,介绍一下这两类的分布式锁解决方案的优缺点。
二、分布式锁的实现原理
2.1 Redis 实现分布式锁
Redis 由于其高性能、使用及部署便利性,在很多场景下是实现分布式锁的首选。首先我们看下 Redis 是如何实现互斥性的。在单机部署的模式下,Redis 由于其单线程处理命令的线程模型,天然的具备互斥能力;而在哨兵 / 集群模式下,写命令也是单独发送到某个单独节点上进行处理,可以保证互斥性;其核心的命令是 set if not exist :
SET lockKey lockValue NX
成功设置 lockValue 的实例,就相当于抢锁成功。但如果持有锁的实例宕机,因为 Redis 服务端并没有感知客户端状态的能力,因此会出现锁无法释放的问题:
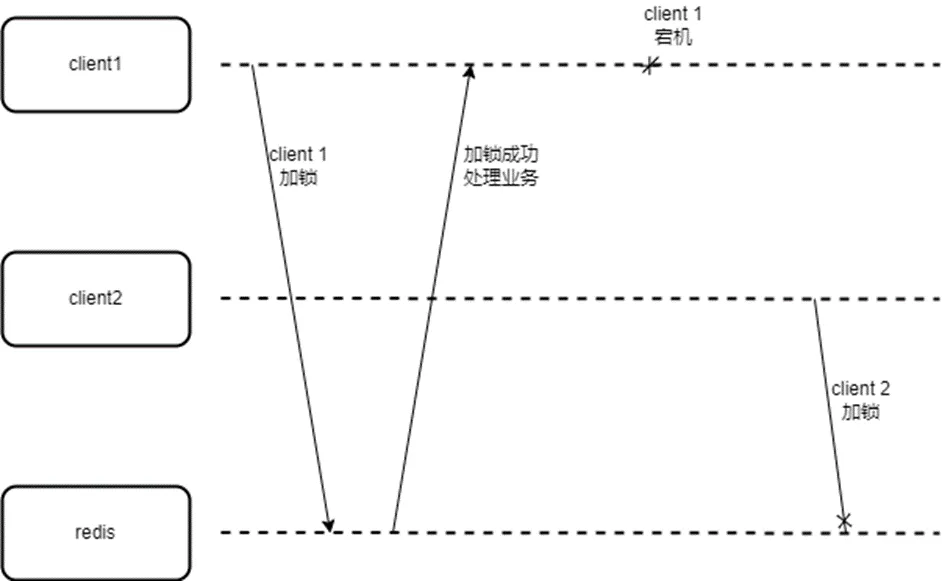
这种情况下,就需要给 key 设置一个过期时间 expireTime:
SET lockKey lockValue EX expireTime NX
如果持有锁的实例宕机无法释放锁,则锁会自动过期,这样可以就避免锁无法释放的问题。在一些简单的场景下,通过该方式实现的分布式锁已经可以满足需求。但这种方式存在一个明显问题:如果业务的实际处理时间比锁过期时间长,锁就会被误释放,导致其他实例也可以加锁:
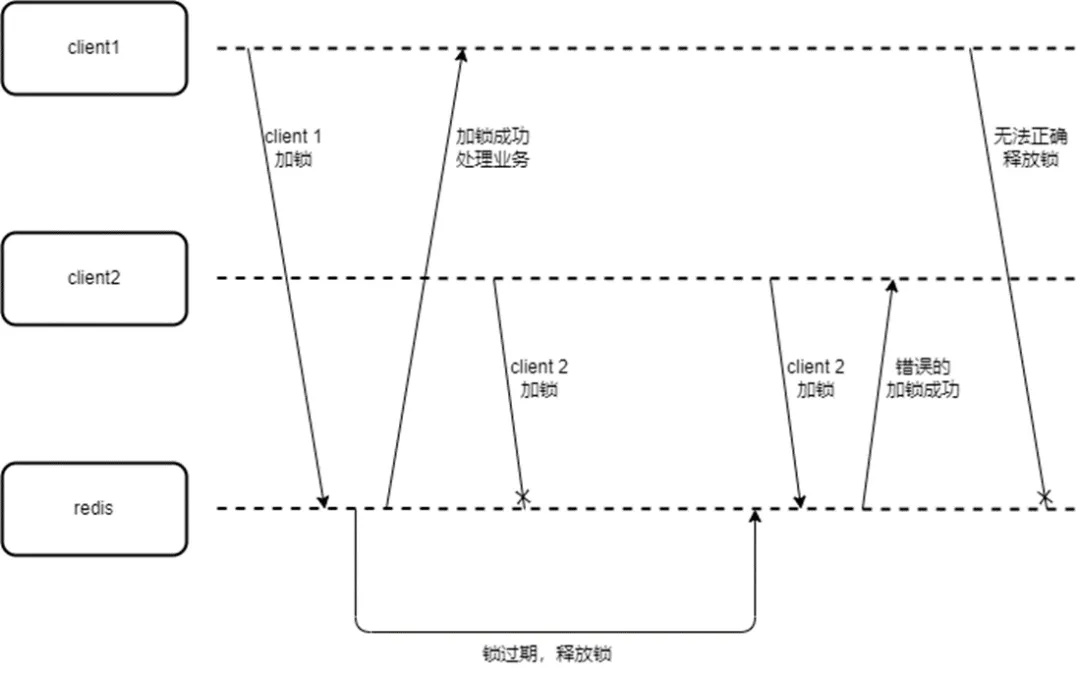
这种情况下,就需要通过其他机制来保证锁在业务处理结束后再释放,一个常用的方式就是通过后台线程的方式来实现锁的自动续期。
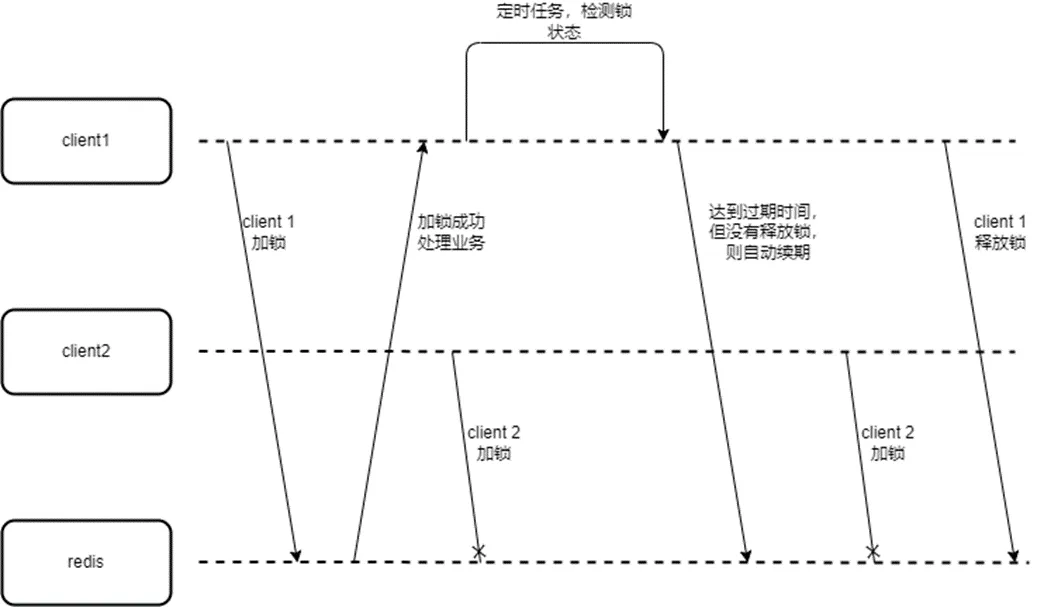
Redssion 是开源社区中比较受欢迎的一个 Java 语言实现的 Redis 客户端,其对 Java 中 Lock 接口定义进行扩展,实现了 Redis 分布式锁,并通过 watchDog 机制(本质上即是后台线程运作)来对锁进行自动续期。以下是一个简单的 Reddison 分布式锁的使用例子:
RLock rLock = RedissonClient.getLock("test-lock");
try {
if (rLock.tryLock()) {
// do something
}
} finally {
rLock.unlock();
}
Redssion 的默认实现 RedissonLock 为可重入互斥非公平锁,其 tryLock 方法会基于三个可选参数执行:
-
waitTime(获取锁的最长等待时长):默认为 - 1,waitTime 参数决定在获取锁的过程中是否需要进行等待,如果 waitTime>0,则在获取锁的过程中线程会等待一定时间并持续尝试获取锁,否则获取锁失败会直接返回。
-
leaseTime(锁持有时长):默认为 - 1。当 leaseTime<=0 时,会开启 watchDog 机制进行自动续期,而 leaseTime>0 时则不会进行自动续期,到达 leaseTime 锁即过期释放
-
unit(时间单位):标识 waitTime 及 leaseTime 的时间单位
我们不妨通过参数最全的 RedissonLock#tryLock (long waitTime, long leaseTime, TimeUnit unit) 方法源码来一探其完整的加锁过程:
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
...
// tryAcquire方法返回锁的剩余有效时长ttl,如果未上锁,则为null
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
if (ttl == null) {
// 获取锁成功
return true;
}
// 计算剩余等待时长,剩余等待时长小于0,则不再尝试获取锁,获取锁失败,后续有多处同样的判断逻辑,将精简省略
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
// 等待时长大于0,则会对锁释放的事件进行订阅,持有锁的客户端在锁释放时会发布锁释放事件通知其他客户端抢锁,由此可得知该默认实现为非公平锁。
// Redisson对Redis发布订阅机制的实现,底层大量使用了CompletableFuture、CompletionStage等接口来编写异步回调代码,感兴趣的读者可以详细了解,此处不作展开
CompletableFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
try {
subscribeFuture.get(time, TimeUnit.MILLISECONDS);
} catch (TimeoutException e) {
...
} catch (ExecutionException e) {
...
}
try {
...
// 循环尝试获取锁
while (true) {
long currentTime = System.currentTimeMillis();
ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return true;
}
...
// 此处通过信号量来将线程阻塞一定时间,避免无效的申请锁浪费资源;在阻塞期间,如果收到了锁释放的事件,则会通过信号量提前唤起阻塞线程,重新尝试获取锁;
currentTime = System.currentTimeMillis();
if (ttl >= 0 && ttl < time) {
// 若ttl(锁过期时长)小于time(剩余等待时长),则将线程阻塞ttl
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
// 若等待时长小于ttl,则将线程阻塞time
commandExecutor.getNow(subscribeFuture).getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
...
}
} finally {
// 取消订阅
unsubscribe(commandExecutor.getNow(subscribeFuture), threadId);
}
}
上述代码逻辑主要集中在处理 waitTime 参数,在并发竞争不激烈、可以容忍一定的等待时间的情况下,合理设置 waitTime 参数可以提高业务并发运行成功率,避免抢锁失败直接返回错误;但在并发竞争激烈、对性能有较高要求时,建议不设置 waitTime,或者直接使用没有 waitTime 参数的 lock () 方法,通过快速失败来提高系统吞吐量。
一个比较值得注意的点是,如果设置了 waitTime 参数,则 Redisson 通过将 RedissonLockEntry 中信号量(Semaphore)的许可证数初始化为 0 来达到一定程度的限流,保证锁释放后只有一个等待中的线程会被唤醒去请求 Redis 服务端,把唤醒等待线程的工作分摊到各个客户端实例上,可以很大程度上缓解非公平锁给 Redis 服务端带来的惊群效应压力。
public class RedissonLockEntry implements PubSubEntry<RedissonLockEntry> {
...
private final Semaphore latch;
public RedissonLockEntry(CompletableFuture<RedissonLockEntry> promise) {
super();
// RedissonLockEntry 中的Semaphore的许可证数初始化为0
this.latch = new Semaphore(0);
this.promise = promise;
}
...
}
获取锁的核心逻辑,会通过 RedissonLock#tryAcquire 方法调用到 RedissonLock#tryAcquireAsync 方法。
private RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
if (leaseTime > 0) {
// 若leaseTime大于零,会设置锁的租期为leaseTime
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {
// 若leaseTime小于或等于零,会设置锁的租期为internalLockLeaseTime,这是一个通过lockWatchdogTimeout配置的值,默认为30s
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime,
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
// 此处的handleNoSync方法是为了解决Redis发生故障转移,集群拓扑改变后,只有持有锁的客户端能再次获得锁的bug,为3.20.1版本修复,详见Redisson issue#4822
CompletionStage<Long> s = handleNoSync(threadId, ttlRemainingFuture);
ttlRemainingFuture = new CompletableFutureWrapper<>(s);
// 根据加锁情况来进行后续处理
CompletionStage<Long> f = ttlRemainingFuture.thenApply(ttlRemaining -> {
// lock acquired
// 若ttl为空,说明加锁不成功
if (ttlRemaining == null) {
if (leaseTime > 0) {
// 若leaseTime>0,则将internalLockLeaseTime变量设置为leaseTime,以便后续解锁使用
internalLockLeaseTime = unit.toMillis(leaseTime);
} else {
// 若leaseTime<=0,则开启看门狗机制,通过定时任务进行锁续期
scheduleExpirationRenewal(threadId);
}
}
return ttlRemaining;
});
return new CompletableFutureWrapper<>(f);
}
// 加锁的lua脚本
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
"if ((Redis.call('exists', KEYS[1]) == 0) " +
"or (Redis.call('hexists', KEYS[1], ARGV[2]) == 1)) then " +
"Redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"Redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return Redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}
可以看到,若 leaseTime 大于 0,则不会开启看门狗机制,锁在过期后即失效,在使用时请务必留意。上述代码中执行的 scheduleExpirationRenewal 方法即为看门狗机制的实现逻辑:
protected void scheduleExpirationRenewal(long threadId) {
// 每个锁都会对应一个ExpirationEntry类,第一次加锁时不存在oldEntry
ExpirationEntry = new ExpirationEntry();
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
// 非首次加锁,重入计数,不作其他操作
oldEntry.addThreadId(threadId);
} else {
// 首次加锁,调用renewExpiration()方法进行自动续期
entry.addThreadId(threadId);
try {
renewExpiration();
} finally {
// 若当前线程被中断,则取消对锁的自动续期。
if (Thread.currentThread().isInterrupted()) {
cancelExpirationRenewal(threadId);
}
}
}
}
private void renewExpiration() {
...
// 此处使用的是netty的时间轮来执行定时续期,此处不对时间轮做展开,感兴趣的读者可详细了解
Timeout task = getServiceManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
...
CompletionStage<Boolean> future = renewExpirationAsync(threadId);
future.whenComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock {} expiration", getRawName(), e);
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
return;
}
if (res) {
// 若续期成功,则递归调用,等待任务的下一次执行
renewExpiration();
} else {
// 若续期结果为false,说明锁已经过期了,或锁易主了,则清理当前线程关联的信息,等待线程结束
cancelExpirationRenewal(null);
}
});
}
// 时间轮的执行周期为internalLockLeaseTime / 3,即默认情况下,internalLockLeaseTime为30s时,每10s触发一次自动续期
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
protected CompletionStage<Boolean> renewExpirationAsync(long threadId) {
// 执行重置过期时间的lua脚本
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (Redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"Redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getRawName()),
internalLockLeaseTime, getLockName(threadId));
}
上面一段代码即是看门狗调度的核心代码,本质上即是通过定时调度线程执行 lua 脚本来进行锁续期。值得留意的是 scheduleExpirationRenewal
方法中的 ExpirationEntry,该对象与锁一一关联,会存储尝试获取该锁的线程(无论是否获取成功)以及重入锁的次数,在锁失效 / 锁释放时,会根据该对象中存储的线程逐一进行资源释放操作,以保证资源的正确释放。
最后,对上述 Redisson 可重入非公平锁源码进行一下总结:
-
Redisson 加锁时,根据 waitTime 参数是否大于 0 来决定加锁失败时采用等待并再次尝试 / 快速失败的策略;
-
Redisson 加锁时根据 leaseTime 参数是否小于等于 0 来决定是否开启看门狗机制进行定时续期;
-
Redisson 底层使用了 netty 实现的时间轮来进行定时续期任务的调度,执行周期为 internalLockLeaseTime / 3,默认为 10s。
2.2 zookeeper 实现分布式锁
zookeeper(后文均简称 zk )基于 zab 协议实现的分布式协调服务,天生具备实现分布式锁的基础条件。我们可以从 zk 的一些基本机制入手,了解其是如何实现分布式锁的。
- zab:为了保证分布式一致性,zk 实现了 zab(Zk Atomic Broadcast,zk 原子广播)协议,在 zab 协议下,zk 集群分为 Leader 节点及 Follower 节点,其中,负责处理写请求的 Leader 节点在集群中是唯一的,多个 Follower 则负责同步 Leader 节点的数据,处理客户端的读请求。同时,zk 处理写请求时底层数据存储使用的是 ConcurrentHashMap,以保证并发安全;
public class NodeHashMapImpl implements NodeHashMap {
private final ConcurrentHashMap<String, DataNode> nodes;
private final boolean digestEnabled;
private final DigestCalculator digestCalculator;
private final AdHash hash;
...
}
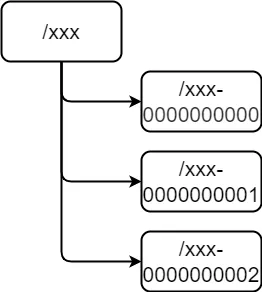
- 临时顺序节点:zk 的数据呈树状结构,树上的每一个节点为一个基本数据单元,称为 Znode。zk 可以创建一类临时顺序(EPHEMERAL_SEQUENTIAL)节点,在满足一定条件时会可以自动释放;同时,同一层级的节点名称会按节点的创建顺序进行命名,第一个节点为 xxx-0000000000,第二个节点则为 xxx-0000000001,以此类推;
- session:zk 的服务端与客户端使用 session 机制进行通信,简单来说即是通过长连接来进行交互,zk 服务端会通过心跳来监控客户端是否处于活动状态。若客户端长期无心跳或断开连接,则 zk 服务端会定期关闭这些 session,主动断开与客户端的通信。
了解了上述 zk 特点,我们不难发现 zk 也是具备互斥性、自动释放的特性的。同时,zk 由于 session 机制的存在,服务端可以感知到客户端的状态,因此不需要有由客户端来进行节点续期,zk 服务端可以主动地清理失联客户端创建的节点,避免锁无法释放的问题。zk 实现分布式锁的主要步骤如下:
-
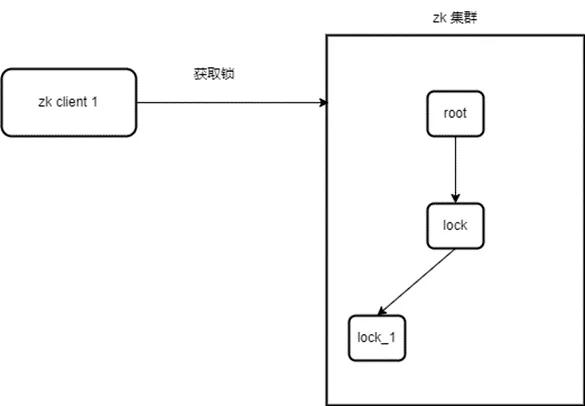
client1 申请加锁,创建 /lock/xxx-lock-0000000000 节点(临时顺序节点),并监听其父节点 /lock;
-
client1 查询 /lock 节点下的节点列表,并判断自己创建的 /xxx-lock-0000000000 是否为 /lock 节点下的第一个节点;当前没有其他客户端加锁,所以 client1 获取锁成功;
-
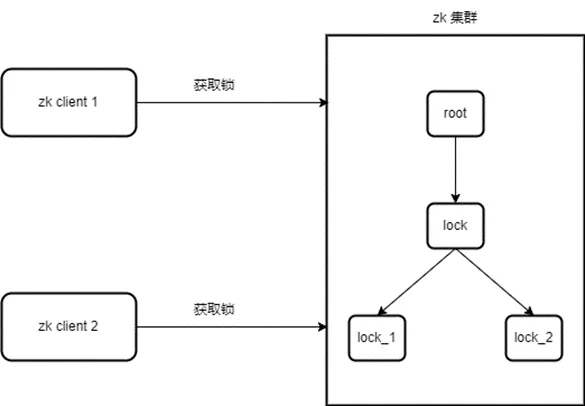
若 client2 此时来加锁,则会创建 /lock/xxx-lock-0000000001 节点;此时 client2 查询 /lock 节点下的节点列表,此时 /xxx-lock-0000000001 并非 /lock 下的第一个节点,因此加锁不成功,此时 client2 则会监听其上一个节点 /xxx-lock-0000000000;
-
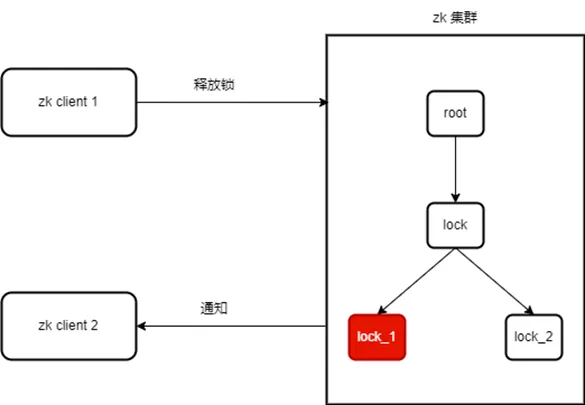
client1 释放锁,client1 删除 /xxx-lock-0000000000 节点,zk 服务端通过长连接 session 通知监听了 /xxx-lock-0000000000 节点的 client2 来获取锁
-
收到释放事件的 client2 查询 /lock 节点下的节点列表,此时自己创建的 /xxx-lock-0000000001 为最小节点,因此获取锁成功。
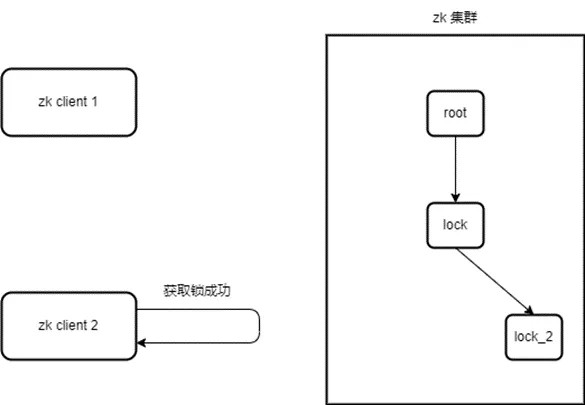
上述是 zk 公平锁的一种常见实现方式。值得注意的是, zk 客户端通常并不会实现非公平锁。事实上,zk 上锁的粒度不局限于上述步骤中的客户端,zk 客户端每次获取锁请求(即每一个尝试获取锁的线程)都会向 zk 服务端请求创建一个临时顺序节点。
以上述步骤为例,如果需要实现非公平锁,则会导致其余的所有节点都需要监听第一个节点 /xxx-lock-0000000000 的释放事件,相当于所有等待锁释放的线程都会监听同一个节点,这种机制无法像 Redisson 一样把唤醒锁的压力分摊到客户端上(或者说实现起来比较困难),会产生比较严重的惊群效应,因此使用 zk 实现的分布式锁一般情况下都是公平锁。